par datajuicer
Open source · 389k downloads · 3 likes
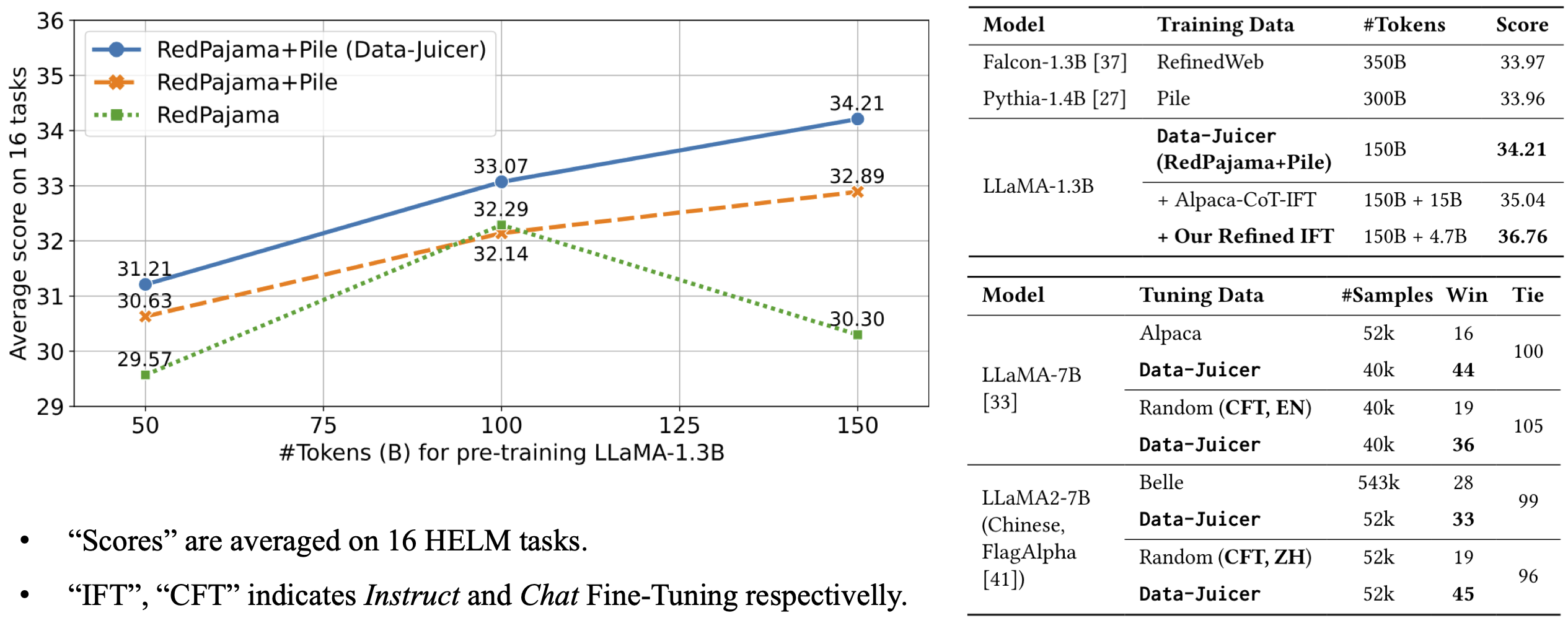
Le modèle LLaMA 1B dj refine 150B est une version affinée du modèle LLaMA-1.3B, spécialement entraînée sur un corpus de 150 milliards de tokens issus de jeux de données raffinés comme RedPajama et Pile. Conçu pour exceller dans des tâches variées, il surpasse plusieurs modèles comparables en performance moyenne sur 16 benchmarks HELM, démontrant une meilleure efficacité malgré un volume de données d'entraînement inférieur. Ses capacités principales incluent la compréhension et la génération de texte de haute qualité, adaptées à des applications nécessitant précision et cohérence. Ce modèle se distingue par son approche centrée sur la qualité des données, optimisant les performances grâce à un prétraitement rigoureux des sources. Il s'adresse particulièrement aux développeurs et chercheurs cherchant un équilibre entre puissance et ressources, idéal pour des projets où la qualité prime sur la quantité brute de données.
Our first data-centric LLM competition begins! Please visit the competition's official websites, FT-Data Ranker (1B Track, 7B Track), for more information.
This is a reference LLM from Data-Juicer.
The model architecture is LLaMA-1.3B and we adopt the OpenLLaMA implementation. The model is pre-trained on 150B tokens of Data-Juicer's refined RedPajama and Pile. It achieves an average score of 34.21 over 16 HELM tasks, beating Falcon-1.3B (trained on 350B tokens from RefinedWeb), Pythia-1.4B (trained on 300B tokens from original Pile) and Open-LLaMA-1.3B (trained on 150B tokens from original RedPajama and Pile).
For more details, please refer to our paper.