par SCUT-DLVCLab
Open source · 43k downloads · 21 likes
Le modèle LiLT-RoBERTa (base) est une solution innovante qui combine un encodeur RoBERTa pré-entraîné en anglais avec un transformateur de mise en page indépendant de la langue, permettant d’adapter des modèles de type LayoutLM à n’importe quelle langue. Il excelle dans l’analyse de documents structurés, comme la classification d’images de documents, l’extraction d’informations ou la réponse à des questions sur des documents, en intégrant à la fois le texte et sa disposition spatiale. Contrairement aux modèles existants, il offre une flexibilité linguistique sans nécessiter de réentraînement spécifique pour chaque langue, tout en restant léger et efficace. Son approche modulaire le rend particulièrement adapté aux environnements multilingues ou aux cas d’usage où la structure visuelle des documents est aussi importante que leur contenu textuel.
Language-Independent Layout Transformer - RoBERTa model by stitching a pre-trained RoBERTa (English) and a pre-trained Language-Independent Layout Transformer (LiLT) together. It was introduced in the paper LiLT: A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding by Wang et al. and first released in this repository.
Disclaimer: The team releasing LiLT did not write a model card for this model so this model card has been written by the Hugging Face team.
The Language-Independent Layout Transformer (LiLT) allows to combine any pre-trained RoBERTa encoder from the hub (hence, in any language) with a lightweight Layout Transformer to have a LayoutLM-like model for any language.
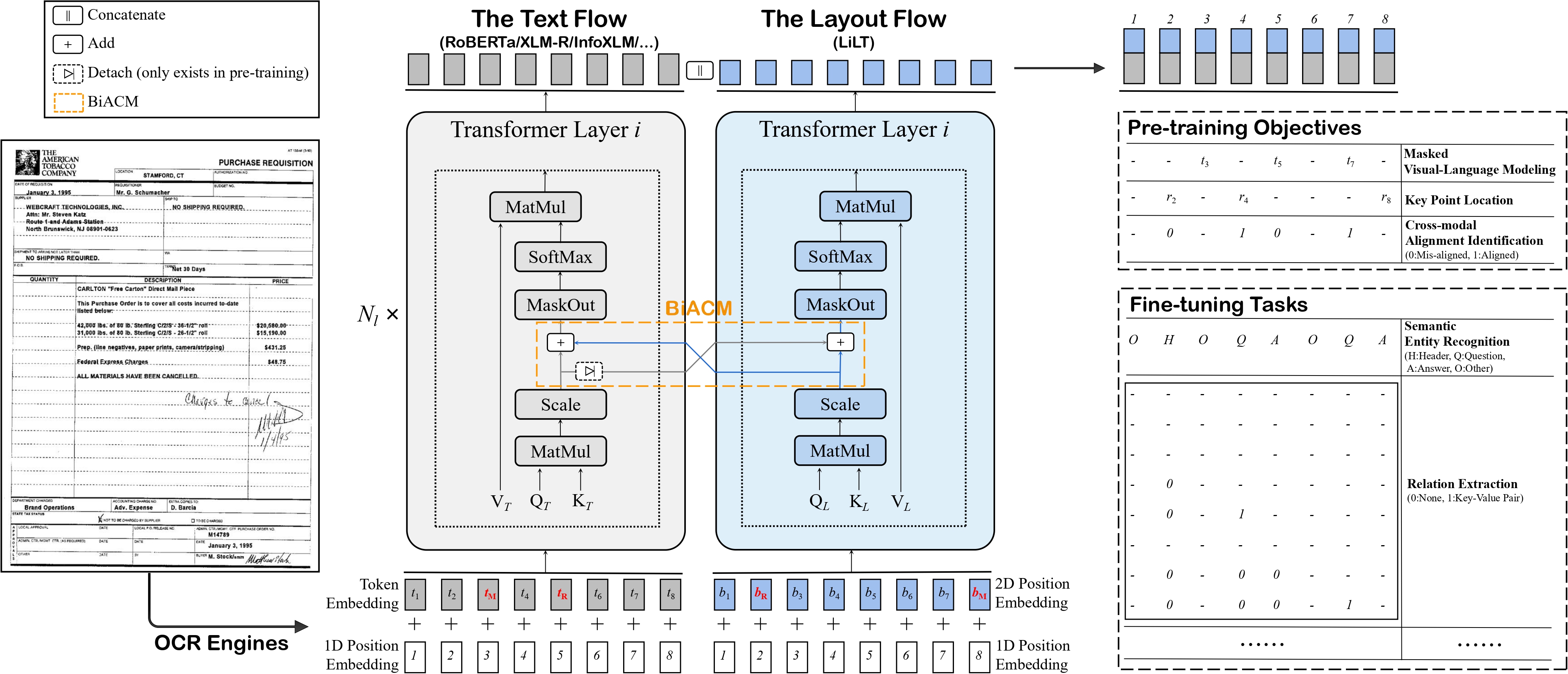
The model is meant to be fine-tuned on tasks like document image classification, document parsing and document QA. See the model hub to look for fine-tuned versions on a task that interests you.
For code examples, we refer to the documentation.
@misc{https://doi.org/10.48550/arxiv.2202.13669,
doi = {10.48550/ARXIV.2202.13669},
url = {https://arxiv.org/abs/2202.13669},
author = {Wang, Jiapeng and Jin, Lianwen and Ding, Kai},
keywords = {Computation and Language (cs.CL), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {LiLT: A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding},
publisher = {arXiv},
year = {2022},
copyright = {arXiv.org perpetual, non-exclusive license}
}