par WhereIsAI
Open source · 1M downloads · 237 likes
UAE Large V1 est un modèle de plongement textuel universel conçu pour générer des représentations vectorielles précises et polyvalentes des phrases en anglais. Il excelle particulièrement dans les tâches nécessitant une compréhension sémantique fine, comme la similarité textuelle ou la recherche d'informations, grâce à une optimisation basée sur des angles pour améliorer la discrimination entre les embeddings. Ce modèle se distingue par ses performances de pointe sur des benchmarks reconnus, notamment en atteignant un score moyen de 64,64 sur le classement MTEB, ce qui en fait un outil fiable pour des applications variées. Ses cas d'usage incluent l'analyse de similarité, la classification de textes ou encore l'intégration dans des systèmes de recherche avancée. Contrairement à des modèles plus spécialisés, UAE Large V1 offre une flexibilité remarquable, adaptée aussi bien aux besoins académiques qu'industriels.
📢 WhereIsAI/UAE-Large-V1 is licensed under MIT. Feel free to use it in any scenario.
If you use it for academic papers, you could cite us via 👉 citation info.
🤝 Follow us on:
Welcome to using AnglE to train and infer powerful sentence embeddings.
🏆 Achievements
WhereIsAI/UAE-Large-V1 achieves SOTA on the MTEB Leaderboard with an average score of 64.64!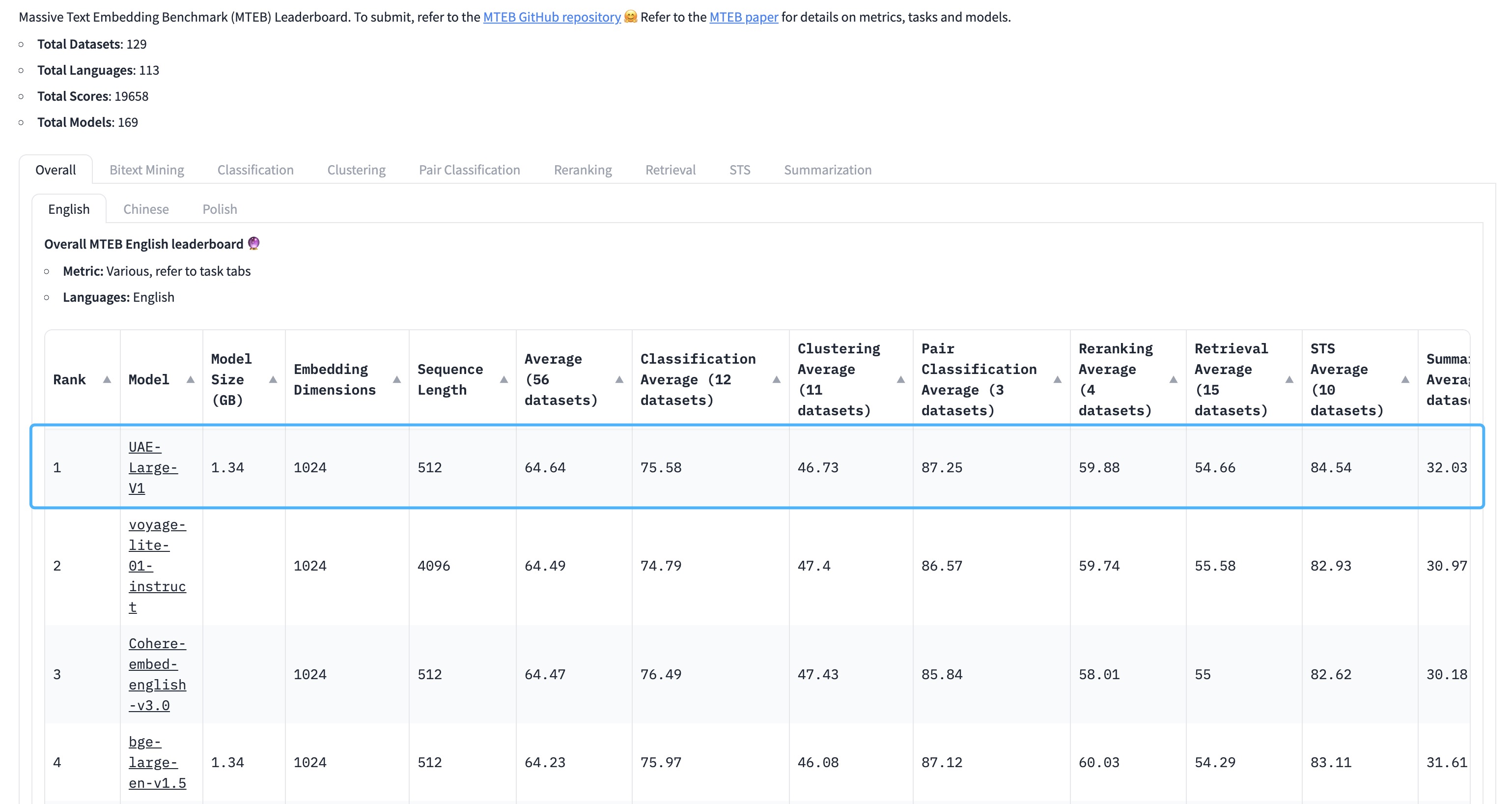
🧑🤝🧑 Siblings:
python -m pip install -U angle-emb
There is no need to specify any prompts.
from angle_emb import AnglE
from angle_emb.utils import cosine_similarity
angle = AnglE.from_pretrained('WhereIsAI/UAE-Large-V1', pooling_strategy='cls').cuda()
doc_vecs = angle.encode([
'The weather is great!',
'The weather is very good!',
'i am going to bed'
], normalize_embedding=True)
for i, dv1 in enumerate(doc_vecs):
for dv2 in doc_vecs[i+1:]:
print(cosine_similarity(dv1, dv2))
For retrieval purposes, please use the prompt Prompts.C for query (not for document).
from angle_emb import AnglE, Prompts
from angle_emb.utils import cosine_similarity
angle = AnglE.from_pretrained('WhereIsAI/UAE-Large-V1', pooling_strategy='cls').cuda()
qv = angle.encode(Prompts.C.format(text='what is the weather?'))
doc_vecs = angle.encode([
'The weather is great!',
'it is rainy today.',
'i am going to bed'
])
for dv in doc_vecs:
print(cosine_similarity(qv[0], dv))
from angle_emb import Prompts
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("WhereIsAI/UAE-Large-V1").cuda()
qv = model.encode(Prompts.C.format(text='what is the weather?'))
doc_vecs = model.encode([
'The weather is great!',
'it is rainy today.',
'i am going to bed'
])
for dv in doc_vecs:
print(1 - spatial.distance.cosine(qv, dv))
Infinity is a MIT licensed server for OpenAI-compatible deployment.
docker run --gpus all -v $PWD/data:/app/.cache -p "7997":"7997" \
michaelf34/infinity:latest \
v2 --model-id WhereIsAI/UAE-Large-V1 --revision "369c368f70f16a613f19f5598d4f12d9f44235d4" --dtype float16 --batch-size 32 --device cuda --engine torch --port 7997
If you use our pre-trained models, welcome to support us by citing our work:
@article{li2023angle,
title={AnglE-optimized Text Embeddings},
author={Li, Xianming and Li, Jing},
journal={arXiv preprint arXiv:2309.12871},
year={2023}
}