LLaMA 1B dj refine 150B
by datajuicer
Open source · 389k downloads · 3 likes
0.8
(3 reviews)ChatAPI & LocalAbout
The LLaMA 1B dj refine 150B model is a refined version of the LLaMA-1.3B model, specifically trained on a corpus of 150 billion tokens drawn from curated datasets such as RedPajama and Pile. Designed to excel in a variety of tasks, it outperforms several comparable models in average performance across 16 HELM benchmarks, demonstrating greater efficiency despite a smaller training data volume. Its core capabilities include high-quality text comprehension and generation, suited for applications requiring precision and consistency. The model stands out for its data-quality-focused approach, optimizing performance through rigorous preprocessing of sources. It is particularly well-suited for developers and researchers seeking a balance between power and resource efficiency, making it ideal for projects where output quality takes precedence over sheer data volume.
Documentation
News
Our first data-centric LLM competition begins! Please visit the competition's official websites, FT-Data Ranker (1B Track, 7B Track), for more information.
Introduction
This is a reference LLM from Data-Juicer.
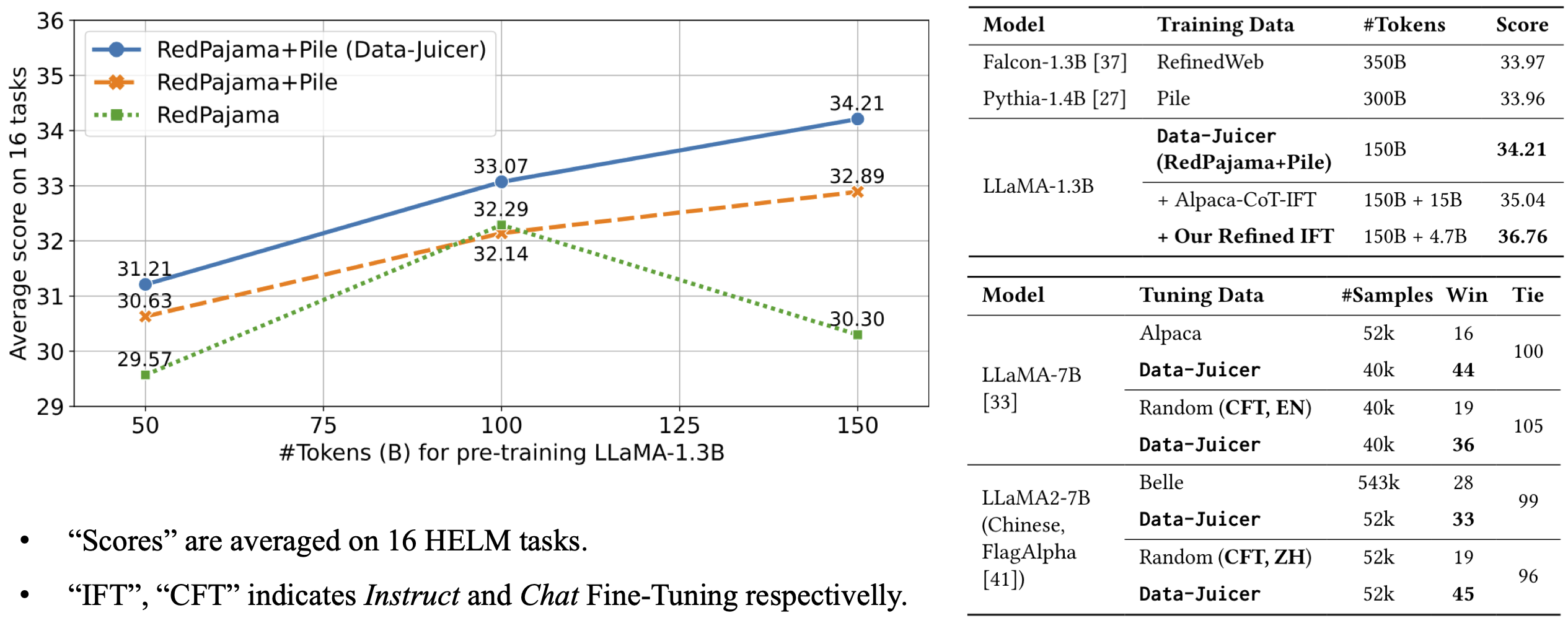
The model architecture is LLaMA-1.3B and we adopt the OpenLLaMA implementation. The model is pre-trained on 150B tokens of Data-Juicer's refined RedPajama and Pile. It achieves an average score of 34.21 over 16 HELM tasks, beating Falcon-1.3B (trained on 350B tokens from RefinedWeb), Pythia-1.4B (trained on 300B tokens from original Pile) and Open-LLaMA-1.3B (trained on 150B tokens from original RedPajama and Pile).
For more details, please refer to our paper.
Capabilities & Tags
transformerspytorchllamatext-generationtext-generation-inferenceendpoints_compatible
Links & Resources