by SCUT-DLVCLab
Open source · 43k downloads · 21 likes
The LiLT-RoBERTa (base) model is an innovative solution that combines a pre-trained English RoBERTa encoder with a language-independent layout transformer, enabling LayoutLM-style models to be adapted to any language. It excels in analyzing structured documents, such as document image classification, information extraction, or question answering on documents, by integrating both text and its spatial layout. Unlike existing models, it offers linguistic flexibility without requiring specific retraining for each language, while remaining lightweight and efficient. Its modular approach makes it particularly well-suited for multilingual environments or use cases where the visual structure of documents is as important as their textual content.
Language-Independent Layout Transformer - RoBERTa model by stitching a pre-trained RoBERTa (English) and a pre-trained Language-Independent Layout Transformer (LiLT) together. It was introduced in the paper LiLT: A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding by Wang et al. and first released in this repository.
Disclaimer: The team releasing LiLT did not write a model card for this model so this model card has been written by the Hugging Face team.
The Language-Independent Layout Transformer (LiLT) allows to combine any pre-trained RoBERTa encoder from the hub (hence, in any language) with a lightweight Layout Transformer to have a LayoutLM-like model for any language.
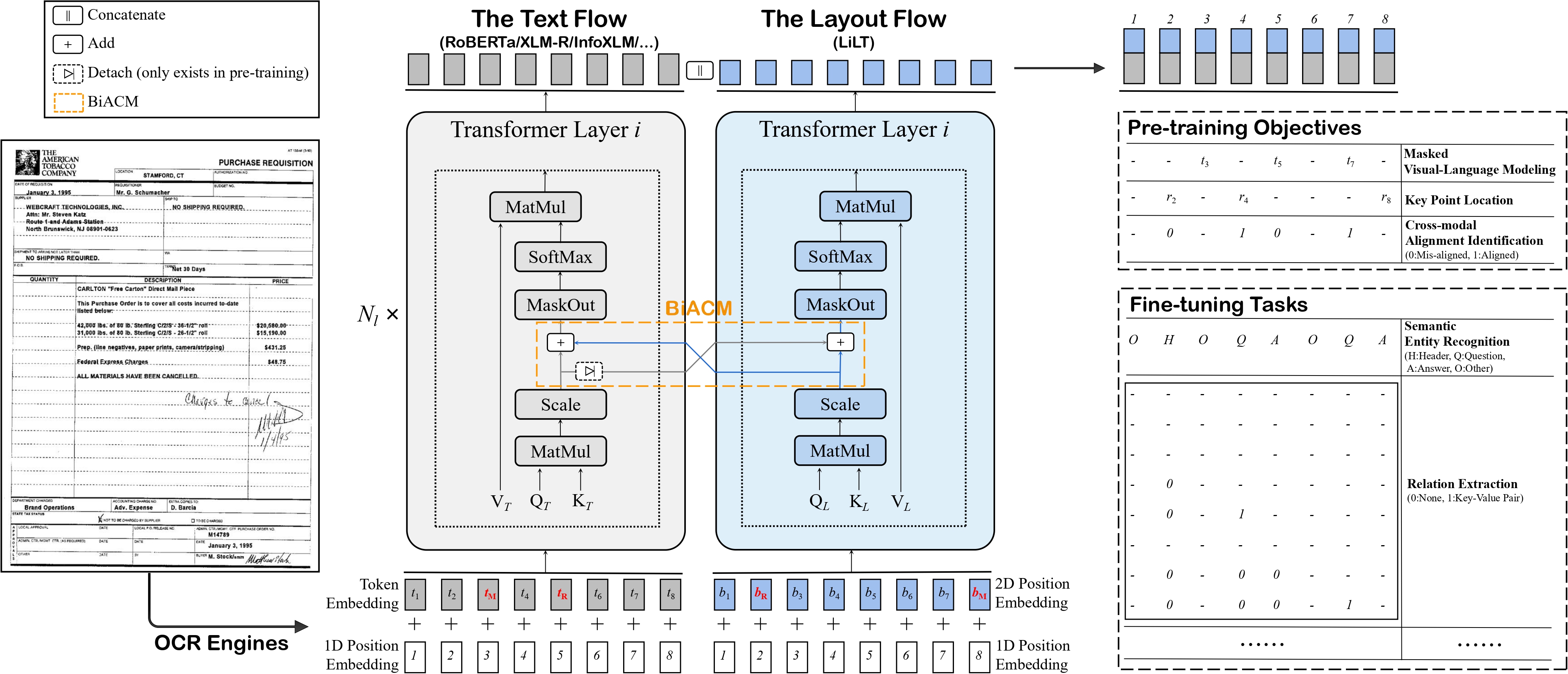
The model is meant to be fine-tuned on tasks like document image classification, document parsing and document QA. See the model hub to look for fine-tuned versions on a task that interests you.
For code examples, we refer to the documentation.
@misc{https://doi.org/10.48550/arxiv.2202.13669,
doi = {10.48550/ARXIV.2202.13669},
url = {https://arxiv.org/abs/2202.13669},
author = {Wang, Jiapeng and Jin, Lianwen and Ding, Kai},
keywords = {Computation and Language (cs.CL), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {LiLT: A Simple yet Effective Language-Independent Layout Transformer for Structured Document Understanding},
publisher = {arXiv},
year = {2022},
copyright = {arXiv.org perpetual, non-exclusive license}
}